Texterkennung
Manchmal ist es notwendig, einen als Bild gescannten Abschnitt aus einem Buch oder anderen Medien als Text bearbeiten zu können. Hierfür wird die Texterkennung (Optical Character Recognition, kurz OCR genannt) benötigt.
Grundsätzlich stehen zwei Varianten für die Texterkennung zur Verfügung:
- Die Texterkennung direkt beim Scan
- Die nachträgliche Texterkennung mit Hilfe eines Programms. Hierbei wird der Text zuerst als PDF gescannt und anschliessend kann der Text erkannt und weiterverarbeitet werden.
Wichtig
Die Ergebnisse der Texterkennung sind, gerade bei Texten mit älterem Schriftsatz, besser, wenn PDF24 verwendet wird, als wenn die OCR-Funktion der Kopiergeräte genutzt wird
Texterkennung direkt beim Scan
Für die Multifunktionsgeräte (Eingangshalle, Kopierraum, Mediothek, etc.) DruckerAllgemein und DruckerKopierraum sind die entsprechenden Anleitungen hier zu finden:
Für die Fachschaftsdrucker in den Lehrerarbeitszimmern kann wie folgt vorgegangen werden:
- Am Gerät die Option Scan wählen
- Die entsprechende Scanoption (per Mail, USB-Speicher, Datei) wählen und ggf. die Empfängermailadresse eingeben
- Im nun erscheinenden Menü als Dateiformat die Option PDF (OCR) wählen
- Die so gescannte Datei kann in einem PDF-Editor geöffnet werden. Der Text kann markiert und in ein Textverarbeitungsprogramm (z.B. Word) kopiert werden.
Texterkennung mit der lokalen PDF24-App
- PDF24 auf dem PC installieren
- Die PDF24-Toolbox öffnen
- Die Option Text per OCR erkennen wählen

- Dateien hinzufügen anklicken
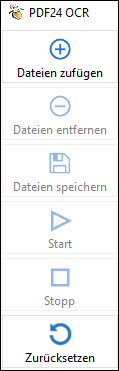
Das PDF auswählen, von dem der Text ausgelesen werden soll
Start klicken
Warten, bis unter Status die Meldung 100% erscheint

- Auf Dateien speichern klicken

Die Datei wird im entsprechenden Pfad als PDF abgelegt
Das PDF kann nun in einem PDF-Editor geöffnet werden. Den Text mit Ctrl + A markieren, mit Ctrl + C zwischenspeichern und mit Ctrl + V in einer beliebigen Datei (z.B. Word) einfügen
Texterkennung mit der PDF24-Browserapp
Die PDF24-Browsertools auf https://tools.pdf24.org/ öffnen
Die Option Text per OCR erkennen wählen
Auf Dateien wählen klicken
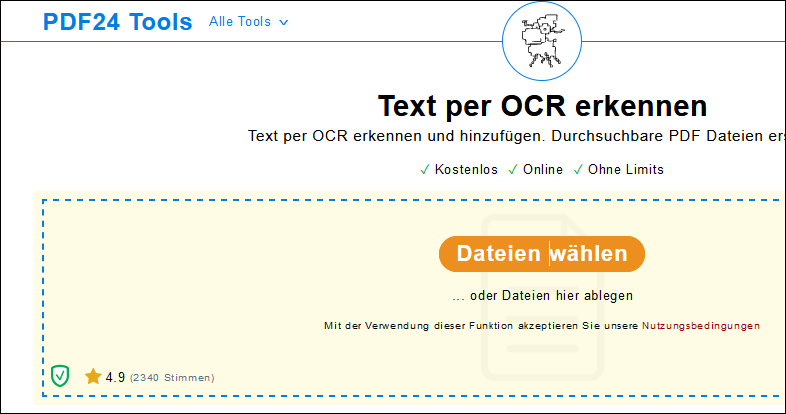
Das PDF auswählen, von dem der Text ausgelesen werden soll
Die Sprache des Dokuments wählen
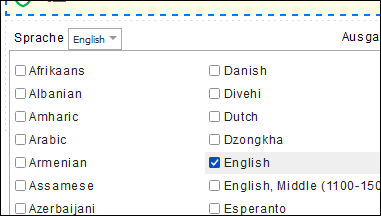
OCR starten klicken
Sobald der Prozess abgeschlossen ist, auf Download klicken
Das heruntergeladene PDF enthält selektierbaren Text
Das PDF kann nun in einem PDF-Editor geöffnet werden. Den Text mit Ctrl + A markieren, mit Ctrl + C zwischenspeichern und mit Ctrl + V in einer beliebigen Datei (z.B. Word) einfügen